本篇主要是面试复习内容的大数据部分。
Hadoop
什么是Hadoop
Hadoop是一个开源软件框架,用于存储大量数据,并发处理/查询在具有多个商用硬件节点的集群上的那些数据。
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统):HDFS允许以一种分布式和冗余的方式存储大量数据。例如,1024MB可以拆分为16*128MB文件,并存储在Hadoop集群中的8个不同的节点上。每个分裂可以复制3次,以实现容错,以便如果1个节点故障的话,也有备份。
MapReduce:是一个计算框架(Google三剑客之一:GFS、BigTable、MapReduce)。它以分布式和并行的方式处理大量的数据。例如,当对所有年龄大于18的用户在上面的1024MB文件中查询时,会有8个Map函数并行运行,以在其128MB拆分文件中提取年龄大于18的用户,然后Reduce函数将运行以将所有单独的输出组合成单个最终结果。Map就是拆解,Reduce就是组装,本治就是分治法。
正常工作的Hadoop集群中都需要启动哪些进程,作用分别是什么
- NameNode:是HDFS的守护进程,负责记录文件是如何分割成数据块,以及这些数据块分别被存储到哪些数据节点上,它的主要功能是对内存以及IO进行集中管理;
- Secondary NameNode:辅助后台程序,与NameNode进行通信,以便定期保存HDFS元数据的快照;
- DataNode:负责把HDFS数据块读写到本地的文件系统;
- JobTracker:负责分配task,并监控所有运行的task;
- TaskTracker:负责执行具体的task,并与JobTracker进行交互;
列举出流行的Hadoop调度器,并简要说明其工作方法
Hadoop调度器的基本作用就是根据节点资源使用情况和作业的要求,将任务调度到各个节点上执行;
调度器需要考虑的因素有三种:
- 作业优先级:作业优先级越高,能够获取到的资源也越多。Hadoop提供了5种作业优先级,分别是
VERY_HIGH、HIGH、NORMAL、LOW、VERY_LOW、VERY_LOW,通过mapreduce.job.priority属性来设置。 - 作业提交时间:作业提交的时间越早,就越先执行;
- 作业所在队列的资源限制:调度器可以分为多个队列,不同的产品线放到不同的队列里运行。不同的队列会设置一个边缘限制,这样不同的队列就会有自己独立的资源,不会出现抢占和滥用资源的情况。
自带调度器有三种:
先进先出调度器(FIFO):
FIFO是Hadoop中默认的调度器,也是一种批处理调度器。它先按照作业的优先级高低,再按照到达时间的先后选择被执行的作业。
容量调度器(Capacity Scheduler):
支持多个队列,每个队列可以配置一定的资源量,每个队列采用FIFO调度策略,为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定;
公平调度器(Fair Scheduler):
支持多队列多用户,每个队列中的资源量可以配置,同一队列中的作业公平共享队列中的所有资源。
- 作业优先级:作业优先级越高,能够获取到的资源也越多。Hadoop提供了5种作业优先级,分别是
简要说一下Hadoop的MapReduce编程模型
首先Map task会从本地文件系统读取数据,转换成key-value形式的键值对集合。使用的是Hadoop内置的数据类型,比如longwritable、text等。然后将键值对集合输入mapper进行业务处理过程,将其转换成需要的key-value再输出。
之后会进行一个partition的分区操作,默认使用的是hashpartitioner,可以通过重写hashpartitioner的getpartition方法来自定义分区的规则;
之后会对key进行sort排序,grouping分组操作将相同key的value合并分组输出;
之后进行combiner归约操作,即一个本地段的reduce预处理,以减小后面shuffle和reducer的工作量;
reduce task通过网络将各个数据收集进行reduce处理,最后将数据保存或者显示,结束整个job。
MapReduce的大致过程:
MapReduce大致可以分为input、split、map、shuffle、reduce、output六个步骤。
- 输入input:输入数据,一般是HDFS上的文件或目录
- 拆分split:切割文件,例如将字符串分割成每个单词
- 映射map:将拆分的内容转换成key-value形式
- 派发shuffle:将key相同的放到一起value是一个序列,这步涉及到数据移动,会将key相同的数据移动到一台机器上
- 缩减recude:将同样key的value序列进行计算
- 输入output:输出结果
为什么要用flume导入HDFS,HDFS的架构是怎么样的
flume是可以实时地导入数据到hdfs中,当hdfs上的文件达到一个指定大小的时候,就会形成一个文件,超过指定时间的话,也会形成一个文件。
文件是存储在DataNode上,NameNode记录着DataNode的元数据信息,而NameNode的元数据信息是存在内存中的。所以,当文件切片很小或者很多的时候,就会卡死。
MapReduce程序运行的时候会有什么比较常见的问题
比如键值对对任务分配不均匀造成的数据倾斜问题。解决的办法是在分区的时候,重新定义分区规则,对于value数据很多的key可以进行拆分、均匀打散等处理,或者是在map端的Combiner中进行数据预处理的操作。
Hadoop的性能调优
- 从应用角度进行优化:
- 避免不必要的reduce任务
- 为job添加一个Combiner
- 根据处理数据特征使用最适合和最简洁的Writable类型
- 重用Writable类型
- 使用StringBuffer而不是String
- 对Hadoop参数进行调优:
- 关闭不必要的linux服务
- 关闭ipv6
- 调整文件最大打开数
- 修改linux内核参数
- 从系统实现角度进行调优:从Hadoop实现机制的角度,发现当前Hadoop设计和实现上的缺点,然后进行源码级的修改。
- 从应用角度进行优化:
HDFS的特点
- 处理超大文件
- 高容错性,运行在廉价机器上
- 横向扩展
- 流式数据处理,而不是随机读写(流式数据读取指的是一个文件只能写一次,后面一直追加,所以每次读取只需要从头开始一直往后读即可)
- 不支持文件修改,只能追加写入
- 对大量的小文件性能不好
- 主从架构,有两种角色namenode和datanode。namenode负责管理存储元数据,处理客户端读写请求;datanode存储真正的数据,执行读写操作;
- 读流程:客户端访问namenode,验证权限,返回数据具体的datanode的地址,客户端访问datanode读取数据;
- 写流程:客户端访问namenode,验证权限并确定文件是否存在,然后先记录到editLog返回输出流对象,客户端最近的一个datanode写数据,每写一个数据块,其余的datanode自己同步
YARN的工作原理,简述其工作方法
YARN全称yet another resource negotiator,即另一种资源调度器。
ResourceManager:
ResourceManager有为所有应用程序仲裁资源的权限的功能,用来代替JobTracker,主要由schedule和ApplicationManager组成。
schedule通过container来分配资源,封装了磁盘、内存、CPU等资源。
ApplicationManager负责接收作业的提交,并申请第一个container来执行作业的ApplicationMaster,并提供失败时重启ApplicationManager的container,而作业的ApplicationMaster向schedule申请资源。
NodeManager:
NodeManager是YARN在每台机器上的代理,负责启动并管理节点上的container,container执行具体的由ApplicationMaster划分的任务。
整体流程:
- 客户端向ResourceManager的ApplicationManager提交程序;
- ResourceManager的ApplicationManager在NodeManager启动第一个container执行ApplicationManager
- ApplicationManager拆分程序,划分成一个个的task,这些task可以在container上运行,然后向ResourceManager申请资源执行task,并向ResourceManager发送心跳;
- 申请到container后,ApplicationMaster会和NodeManager通信,并将task发送到对应的container执行,task会向ApplicationMaster发送心跳;
- 程序执行完成,ApplicationMaster会向ResourceManager注销并释放资源;
Spark
Spark有几种部署模式,每种模式的特点
- local模式(本地模式):运行在一台机器上,常用于本地开发测试,本地模式还分为local单线程和local-cluster多线程;
- standalone模式(集群模式):典型的Master/Slave模式,起初Master是有单点故障的;
- yarn模式(集群模式):运行在yarn资源管理器框架之上,由yarn负责资源管理,Spark负责任务调度和计算;
- mesos模式(集群模式):运行在mesos资源管理器框架之上,由mesos负责资源管理,Spark负责任务调度和计算;
Spark为什么比MapReduce快(Run workloads 100x faster)
- Spark是基于内存计算的,减少了低效的磁盘交互;而MapReduce是基于磁盘的迭代。
- MapReduce的设计:中间结果保存在文件中,提高了可靠性,减少了内存占用,但是牺牲了性能;
- Spark的设计:数据在内存中进行交换,要更快一些,所以性能要比MapReduce好,但是内存的可靠性不如磁盘;
- 高效的调度算法,基于DAG;
- 容错机制Linage;
- Spark是基于内存计算的,减少了低效的磁盘交互;而MapReduce是基于磁盘的迭代。
Spark有哪些组件
master:管理集群和节点,不参与计算worker:计算节点,进程本身不参与计算driver:运行程序的Main方法,创建spark context对象spark context:控制整个application的生命周期,包括dag sheduler和task scheduler等组件client:用户提交程序的入口
Hadoop和Spark的shuffle相同和差异
- 高层面:两者并没有太大的差别,都是将
mapper的输出进行partition,不同的是partition是送到不同的reducer里。 - 低层面:Hadoop是
sort-based,在进入combine()和reduce()之后,必须先排序;Spark默认是hash-based,通常使用HashMap来对shuffle来的数据进行汇总,不需要提前排序; - 实现角度:Hadoop MapReduce需要将处理流程划分成明显的几个部分:
map、split、merge、shuffle、sort、recude,而Spark没有这样功能明确的阶段;
- 高层面:两者并没有太大的差别,都是将
RDD宽依赖和窄依赖
- 窄依赖:每一个parent RDD的Partition最多被子RDD的一个Partition使用(即一父一子)
- 宽依赖:多个子RDD的Partition会依赖同一个parent RDD的Partition(一父多子)
cache和pesist的区别
cache和persist都是用于缓存RDD,避免重复计算,
.cache()==.persist(MEMORY_ONLY)RDD有哪些缺陷
- 不支持细粒度的写和更新操作:Spark写数据是粗粒度的,就是批量写入数据,但是读数据可以细粒度
- 不支持增量迭代计算(Flink)支持
RDD有哪几种操作类型
Spark的工作机制
Spark的优化怎么做
Spark中数据的位置是被谁管理的
Spark的数据本地性有哪几种
Spark的常用算子区别
Transformation和action是什么,有什么区别,举出一些常用方法
Spark on Yarn模式有哪些优点
描述Yarn执行一个任务的过程
Storm
- Storm的工作原理是什么
- 流的模式是什么?默认是什么?
- Storm Group分类
- Storm的特点和特性是什么
- 编程简单:开发人员只需要关注应用逻辑,而且跟Hadoop类似,Storm提供的编程语言也很简单
- 高性能,低延迟:可以应用于广告搜索引擎等要求实时响应的场景
- 分布式:可以轻松应对数据量大,单机搞不定的场景
- 可拓展:随着业务的发展,数据量和计算量越来越大,系统可水平扩展
- 容错:单个节点挂了是不影响应用的
- 消息不丢失:保证了消息处理
- Storm组件有哪些
Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
Kafka的设计是怎么样的
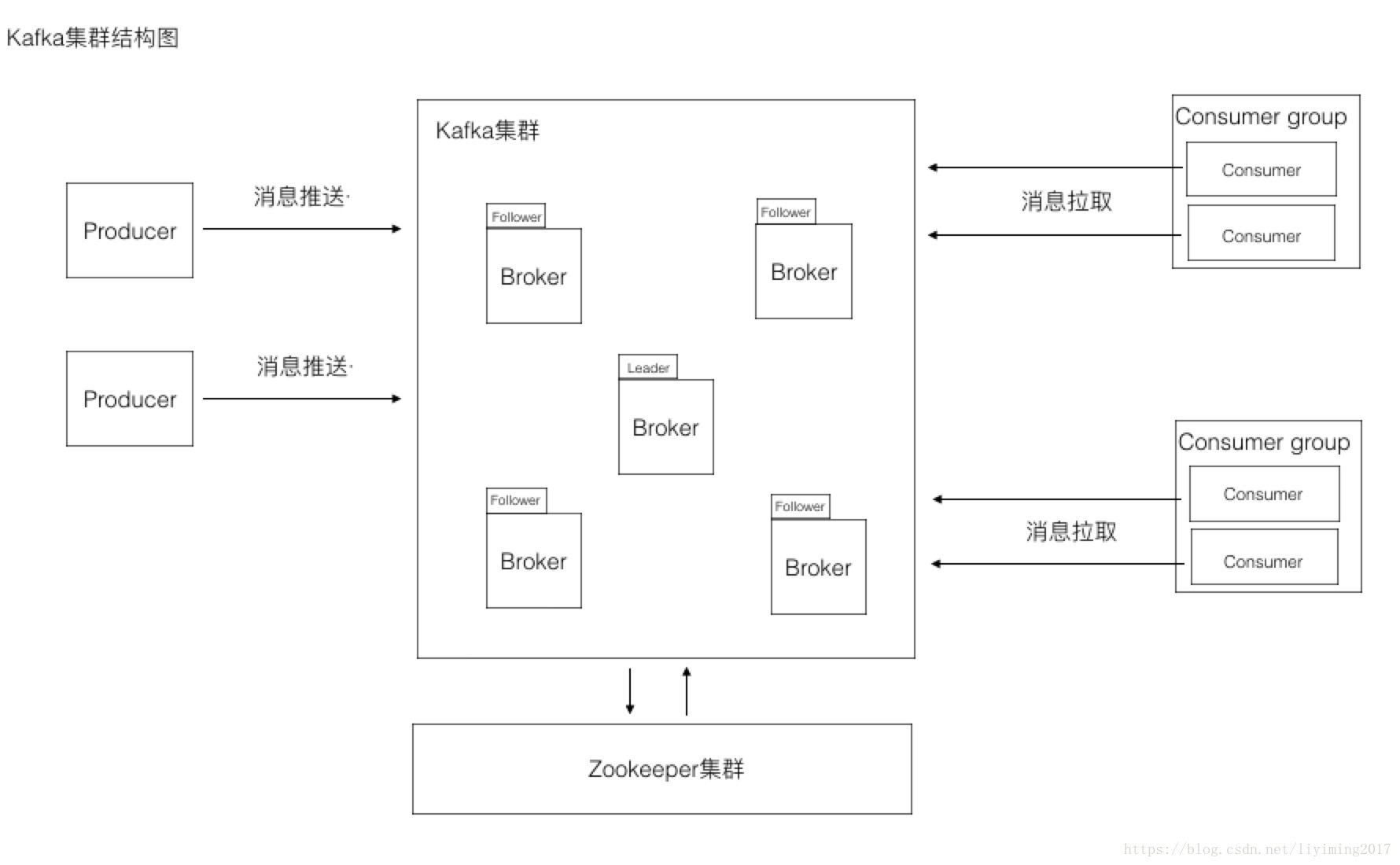
![Kafka的设计结构]() Kafka的设计结构
Kafka的设计结构- Kafka是可以配合zookeeper集群进行工作的
- Kafka集群中有若干个Broker,其中一个是leader,其它的是follower
- Consumer外面还包裹了一层Consumer Group
数据传输的事物定义有哪三种
Kafka判断一个节点是否还活着的两个条件
Kafka与传统消息系统之间的三个关键区别
Kafka高消息文件存储设计的特点
Kafka有哪几个组件
- Broker:Kafka集群包含一个或者多个服务器,这种服务器被称为broker
- Topic:每条发布到Kafka集群的消息都有一个类别,类别就被称为是topic(物理上topic是分开存储的)
- Partition:是一个物理上的概念,每个Topic包含一个或者多个Partition
- Producer:负责发布消息到Kafka broker上
- Consumer:消息消费者,向Kafka broker读取消息的客户端
- Consumer Group:每个Consumer都属于一个特性的Consumer Group
Kafka的特性
- 以时间复杂度为\(O(1)\)的方式提供消息持久化能力,即使TB以上的数据也能保证常数的时间复杂度的访问性能
- 高吞吐率:即使在廉价的机器上也能支持高吞吐率的传输
- 支持Kafka Server间的消息分区以及分布式消费,同时保证每个Partition内的消息顺序传输
- Scale out:支持在线水平扩展
Kafka的应用场景
- 构建可在系统或者应用程序之间可靠获取数据的实时流数据管道
- 构建实时流应用程序,可以转换或者响应数据流
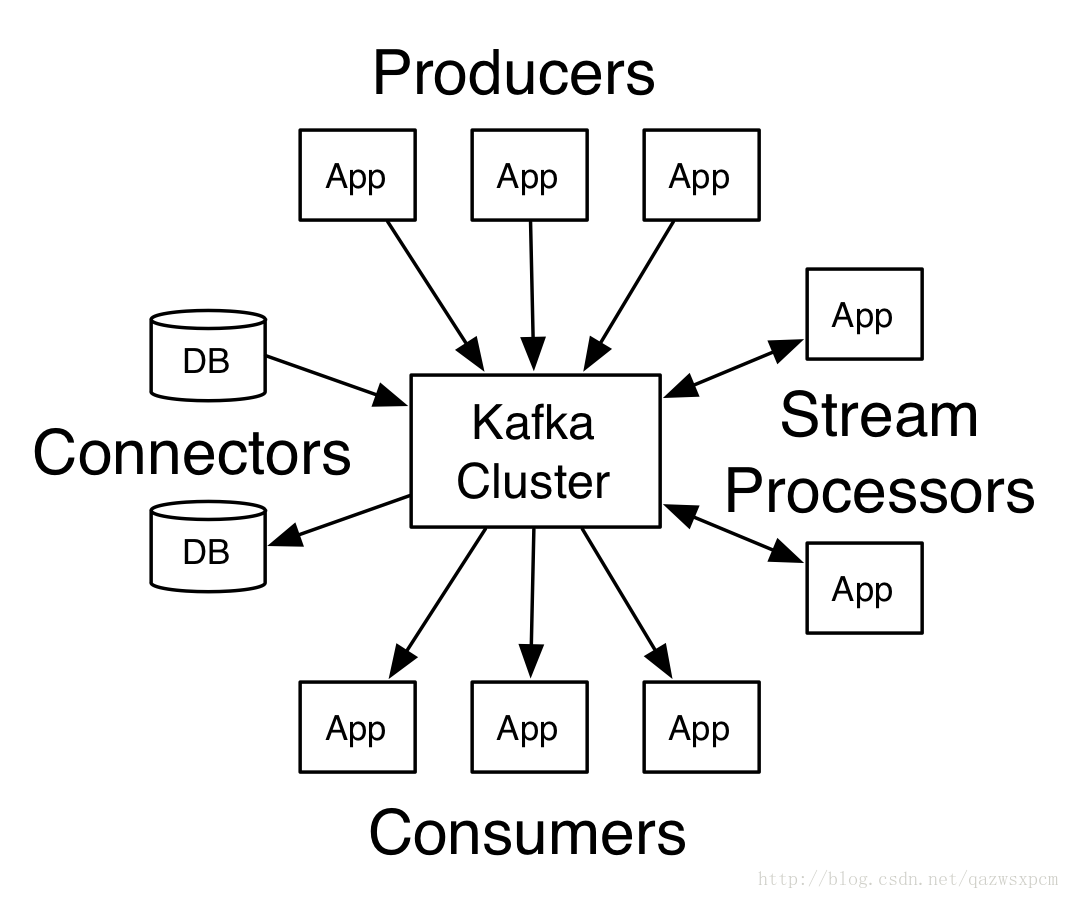
Kafka四个核心api
- Producer:使用Producer API发布消息到1个或者多个topic中
- Consumer:应用程序使用Consumer API订阅一个或者多个topic,并处理产生的消息
- Streams:使用Streams API充当一个流处理器,从1个或多个topic消息输入流,产生一个输出流到1个或者多个topic,有效地将输入流转化为输出流
- Connector:允许构建或者运行可重复使用的生产者或者消费者,将topic连接到现有的应用程序或者数据系统
![Kafka的四个核心API]() Kafka的四个核心API
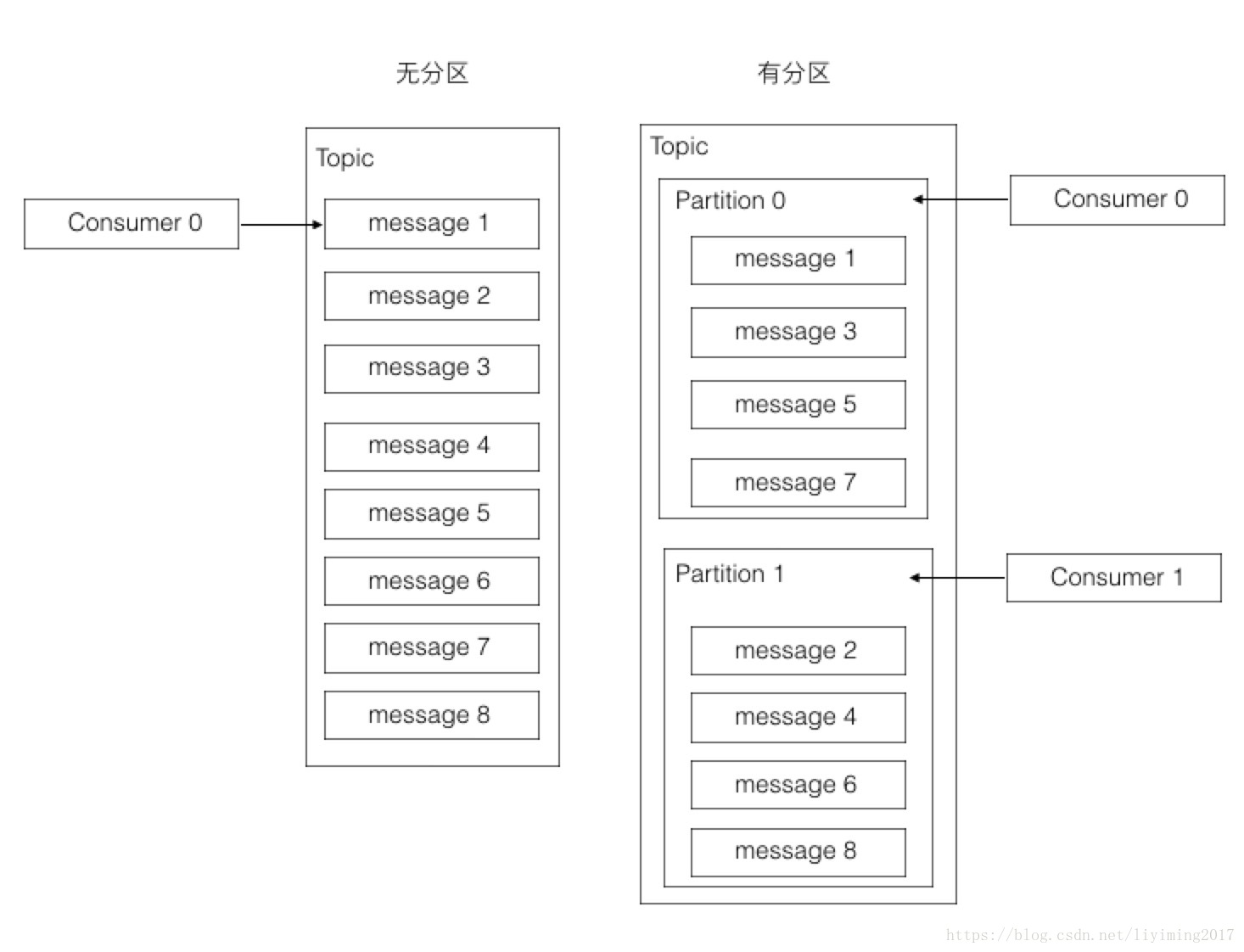
Kafka的四个核心APIKafka分区的概念
大多数消息系统,在同一个topic下的消息,都会存储在一个队列中。而分区的概念就是**把这个队列划分为若干个小的队列,每一个小的队列就是一个分区。
创建分区的好处就是可以让多个消费者同时消费,这样速度就大大提升。
![Kafka分区的概念]() Kafka分区的概念
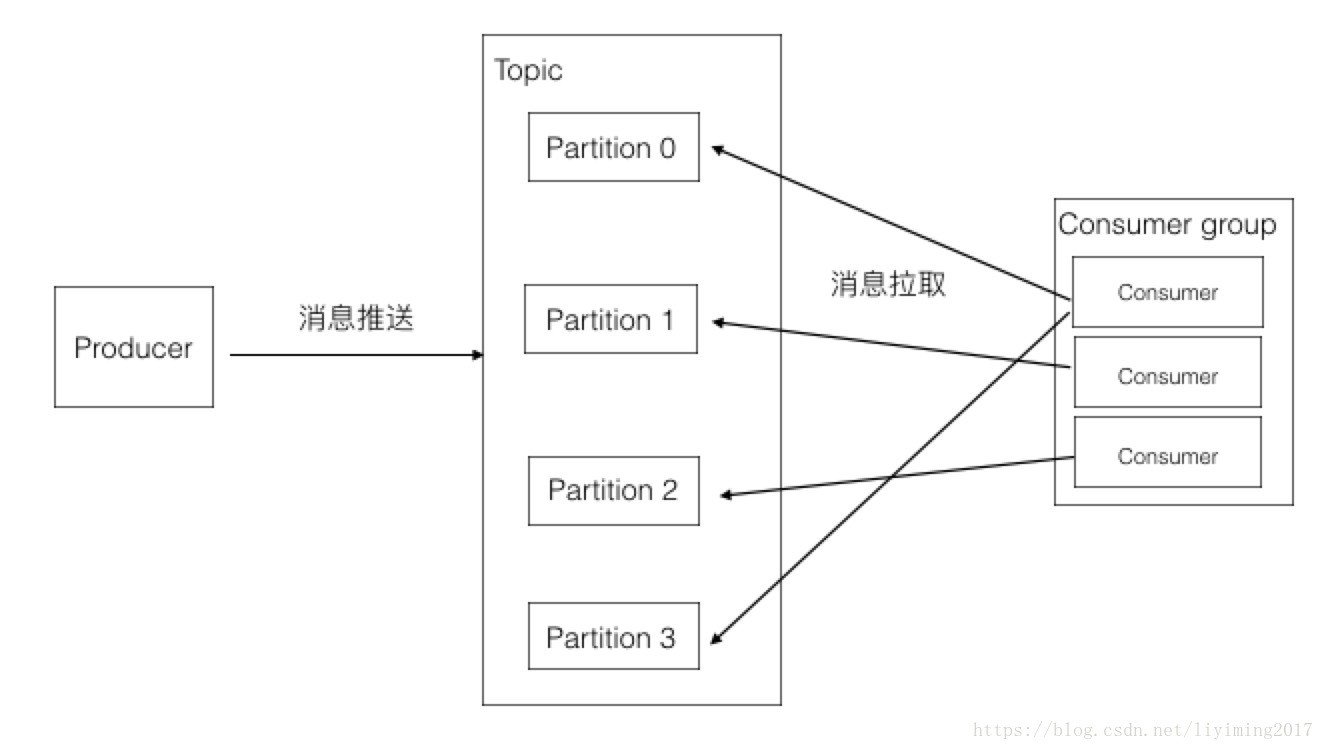
Kafka分区的概念分区有以下几个特征:
- 一个partition只能被同组的一个consumer对象消费
- 同一个组里的consumer可以消费多个partition
- 消费效率最高的情况是partition和consumer的数量相等,这样可以保证每个consumer都专职负责一个partition
- consumer数量是不能大于partition的数量的,不然就会有consumer闲置
- consumer group是一个订阅者的集群,其中的每个consumer负责自己消费的分区
![Kafka分区的特征]() Kafka分区的特征
Kafka分区的特征
ZooKeeper
ZooKeeper是一个经典的分布式数据一致性解决方案,致力于为分布式应用提供一个高性能、高可用,且具有严格顺序访问控制能力的分布式协调服务。 分布式应用程序可以基于ZooKeeper实现数据发布与订阅、负责均衡、命名服务、分布式协调与通知、集群管理、Leader选举、分布式锁、分布式队列等功能。
ZooKeeper都要哪些功能
统一命名服务(naming)
分布式应用中,通常需要一套完整的命名规则,既能够产生唯一的命名便于记住,又不需要将名称关联到特定的资源上,类似数据库中产生的唯一的主键。
配置管理
配置信息可以交个Zookeeper来管理,将配置信息保存在Zookeeper中的某个目录节点中,然后将所有需要修改的应用监控配置信息的状态。一旦配置信息发生变化,每台应用就会收到Zookeeper的通知,获取新的配置信息应用到系统中。
集群管理
Zookeeper不仅能够帮助维护当前的集群中机器的服务状态,而且能够帮助选出一个Master来管理集群。
对列管理
- 当一个队列的成员都聚齐时,这个队列才可用,否则就需要一直等待,这就是同步队列。
- 队列按照FIFO方式进行出队和入队操作,例如实现生产者和消费者模型。
ZooKeeper怎么保证主从节点的状态同步
ZooKeeper有几种部署模式
- 单机部署:一台集群上运行;
- 集群部署:多台集群上运行;
- 伪集群部署:一台集群启动多个ZooKeeper实例运行
ZooKeeper的通知机制
集群中有 3 台服务器,其中一个节点宕机,这个时候 Zookeeper 还可以使用吗
两阶段提交和三阶段提交的过程
ZooKeeper宕机如何处理
获得分布式锁的流程
ZooKeeper队列管理
ZooKeeper下Server的工作状态
ZooKeeper是如何保证事务的顺序一致性的
ZooKeeper负载均衡和nginx负载均衡区别
Flink
Flume
Hive
Hive中存放的是什么
Hive中存放的是表,存的是和hdfs的映射关系,hive是逻辑上的数据仓库,实际操作的是HDFS上的文件,HQL是用sql语法编写的MapReduce程序。
Hive与关系型数据库的关系
没有任何关系,hive是数据仓库弥,不能和数据库一样进行实时的CRUD操作,是一次写入多次读取的操作。
Hive表关联查询,如何解决数据倾斜的问题
倾斜原因:map输出数据,按照key的Hash值分配到reduce中。由于key分布不均匀、业务数据本身的特性、建表时考虑不周等等原因造成的reduce上的数据量差异过大。
- key分布不均匀
- 业务数据本身的特性
- 建表时考虑不周
- 某些SQL语句本身就会有数据倾斜
解决方案:
- 参数调节:有数据倾斜的时候进行负载均衡
- SQL语句调节:
- 选择
join key分布最均匀的表作为驱动表,做好裁剪、filter等操作,以达到两表做join的时候,数据量相对变小的效果 - 大表
join小表:把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上 count distinct大量相同的特殊值- 大小表
join:使用map join让小的维度表先进内存,在map端完成reduce。
- 选择
Hive的HSQL转换为
MapReduce的过程- SQL Parser:(将HQL转换成抽象语法树)定义SQL的语法规则,完成SQL语法,语法解析,将SQL转化为抽象语法树AST Tree
- Semantic Analyzer:(将抽象语法树转换成查询块)遍历AST Tree,抽象出查询的基本组成单元QueryBlock
- Logical Plan:(将查询块转换成逻辑查询计划)遍历QueryBlock,翻译为执行操作树OperatorTree
- Logical Plan Optimizer:(重写逻辑查询计划)逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量;
- Physical Plan:(将逻辑计划转成物理计划)遍历OperatorTree,也就是翻译为MapReduce任务;
- Logical Plan Optimizer:物理层优化器进行MapReduce任务的变换,生成最终的执行计划;
Hive特点
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,无需专门开发MapReduce应用,但是不支持实时查询。
Hive内部表和外部表的区别
- 创建表时:创建内部表,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做出任何改变;
- 删除表时:内部表的元数据会和数据一起删除,外部表只是删除数据元数据,不删除数据。
Hive底层与数据库的交互原理
由于Hive的元数据可能要面临不断地更新、修改和读取操作,所以它显然不适合使用Hadoop文件系统进行存储。所以,目前Hive是将元数据存储在RDBMS中,比如存储在MySQL中。元数据的信息包括:存在的表、表的列、权限和更多信息。
Hbase
Pig
Sqoop
Kylin
布隆过滤器
布隆过滤器(Bloom Filter)是一个节省空间的概率数据结构,用来测试一个元素是否在一个集合里。它实际上是一个很长的二进制向量和一系列随机映射函数。相比于传统的List、Set、Map等数据结构,它更高效、占用空间更少,但是缺点是返回的结果是概率性的,不是确定的。
原理
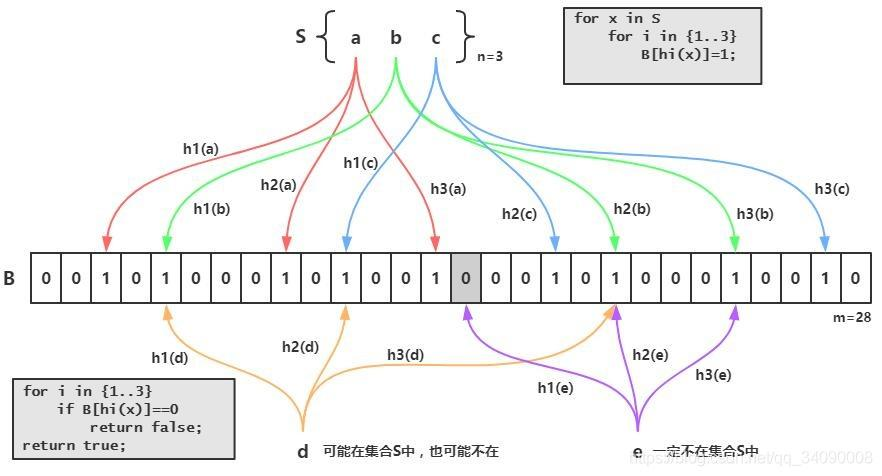
插入
当一个元素要被加入到集合中时,需要通过K个Hash函数将这个元素映射成一个位数组中的K个点,把它们置为1
查找
当需要查找某个元素时,首先需要判断其是否存在,只要看这些点是不是都是1就可知道集合中是否含有它。如果这些点有任何一个0,都说明被查找的元素不存在;如果都是1,则被检的元素很可能存在。
运用场景
- 解决了redis等其它缓存穿透的问题
- 判断是否存在该行或者列,以减少对磁盘的访问,提高数据库的访问性能
- 分布式数据库BigTable使用了布隆过滤器来查找不存在的行或者列,可以减少磁盘查找的IO次数
优缺点
优点:
- 节省存储空间
- 查找速度快
缺点:
- 存在误判:因为可能hash之后得到的k个位置都是1,但是要查到的元素并没有在容器中
- 删除困难:一个放入的容器中的元素映射到bit数组的k个位置上都是1,所以删除的时候并不能简单地直接设置为0,因为这样会影响其它元素的判断